
We wear glasses to better focus on what we’re looking at, and we wear sunglasses to filter out harmful rays, reduce glare, and see better. Why do we allow raw sound into our ears without any filtering or focus at all? Wouldn’t it be amazing to fine tune everything we hear and how we hear it, regardless of it’s source? Fortunately, now we can.
Introducing Bion, the Universal Audio Interface for all of life’s sounds.
A universal audio interface that can accept streamed audio data from n sources simultaneously and control or shape each source independently would obviously be the ideal to shoot for. So if that’s the target, let’s see what it would actually take to hit that bullseye. Let’s define the inputs and outputs.
First, there would obviously need to be some constraint on what n is for a variety of reasons. First, there’s the hardware requirements of processing a large number of distinct streams simultaneously, and more importantly, your brain can only process so much data at a time effectively. For arguments sake, let’s say n=4 (per ear) for this discussion. What would that mean? Well, there’s the world around you to be heard, and it should be heard better and with more clarity and control with audio augmentation than without. In the design of Bion, there are 3 triangulated ambient mics per ear. Each of these is a separate input, and these inputs help to directionalize, isolate, focus or eliminate sounds in the environment, maximizing situational awareness. Fortunately for your brain, these three mics are merged based on a programmable sound profile into a single stream that optimizes each sound’s direction transparently, and the flavor or color of that composite sound is shaped as a single stream, acting as a single source.
Next, there’s the command, control, and communication (3c) mic, located in the Cymba of your ear. It picks up what you say, and decides what to do with that data. If it’s a command, it’s executed. If it’s part of an active conversation, it’s transmitted. If it’s just part of you talking to someone nearby it simply ignores the input. For commands and outbound voice data, we’ll send it out flat, and let the receiver contour it if desired. This means it does not require shaping, saving a processing slot.
That takes care of direct inputs, but what about other inputs, like music, or speaking with (and listening to) others who are remote, or listening to other stored or streamed content? There are 3 additional independently controllable streams that can happen simultaneously. We can apply any kind of shaping algorithm we want to them – either dynamically or automatically.
Why is all this needed? Why should anyone really care how things sound?
Consider this; More sounds enter our consciousness now from more varied sources simultaneously than ever before in human history. Some are welcome, some are not. Even today, we’re seeing an uptick in the sale of devices designed to prevent you from hearing sounds. People are experiencing severe sound induced damage to their auditory nerve by sounds outside their control, as well as self-inflicted damage by too-loud and poor quality headphones and earbuds.
The best scenario is the the ability to dynamically and intentionally set the ‘thresholds’ and the ‘transparency’ of the sound sources you hear. Whether these sounds come from your direct environment, or from other locally stored or remote sources, you choose be aware of their presence, but not overwhelmed by them. You get to decide the sound’s importance to you, not the sound’s originator. The ability to isolate on, and enhance the sounds that you actually want to hear is more important now than ever before too.
So, lots of sounds from lots of places. Some from right around us, and some streamed in from remote locations. How do we control all these sounds? With our voices, of course. Spoken interfaces are the obvious evolution of man/machine interaction, so let’s not dally and waste energy developing even more elaborate (but still annoying) menus under glass. They consume far too much attention to operate, which is why they are banned from use while driving, as they should be. Sp0k3n is the voice interface of Bion, programmed in a new language called ‘v’. Sp0k3n can learn from the sounds it hears, and it can categorize them into profiles that can be summoned and applied at will, and even automatically based on factors you determine, such as frequencies, dB levels, or even geolocation.
Sp0k3n stores experienced soundscapes for detailed analysis later, where visual interaction with the data actually makes sense, e.g. in the non-mobile environment that Bion assumes when plugged into it’s base station. In this mode, the base station’s processor combines with the processors of the mobile ear-worn components to function as a single multi-processor desktop system, with monitor and typical input devices like keyboard, mice, space-mice, controllers, etc. Bion is in fact your personal computer. In this configuration, sound environments can be manipulated visually and profiles can be created to understand and control these when similar environments are experienced again. These can be shared with others in real-time if desired, so if someone has already crafted a soundscape for a specific environment, they can share it with you in that space and you can use it as a base to begin tweaking it to your liking with voice commands.
All of that speaks to various sounds coming in, and the adjusting of those sounds to our liking. But how do those disparate sounds come in, and what mechanisms should be employed for that?
Bion is extensible by design. The ear-worn components, left and right audio computers, in their base configurations, provide ambient sound control, simultaneous stored audio playback, and a near-field wireless mechanism for wireless interaction with and between them, and short-distance connectivity with other users/devices. But that is just the base system platform. Modularity is the important thing here. Additional super-thin extended-functionality-boards (efb’s) are pluggable onto the base platform, sandwich-like, enhancing the capabilities of the system in whatever way is desired. These efbs are stackable, and are used to build use-specific devices.
For example, a cellular efb in the left ear gives LTE or GSM capabilities to the system, while a WiFi efb in the right allows full networking capability. Each device can have matching or different efbs as desired, to build up a complete system for any capability desired. Each efb can leverage the capabilities of other installed efbs, such as hardware encryption, cameras, advanced FPGAs for user defined tasks, such as audio stream filtering, or real-time facial recognition, or can provide additional local storage, etc. The extensibility and tailor-ability to various needs is essentially unlimited.
So, we’ll need a very low-profile, multi-pin interconnect system so these efbs can stack efficiently, physically securely, yet repeatably plugged and unplugged in the field to tailor the devices for the desired functionality at will.
The answer here is a morph of BGA into a new kind of flexible interconnect system. For that, we look to biology for assistance, and examine the interconnect system that a female human’s placenta employs in connection with the womb, as can be seen in this magnificent drawing by DaVinci:
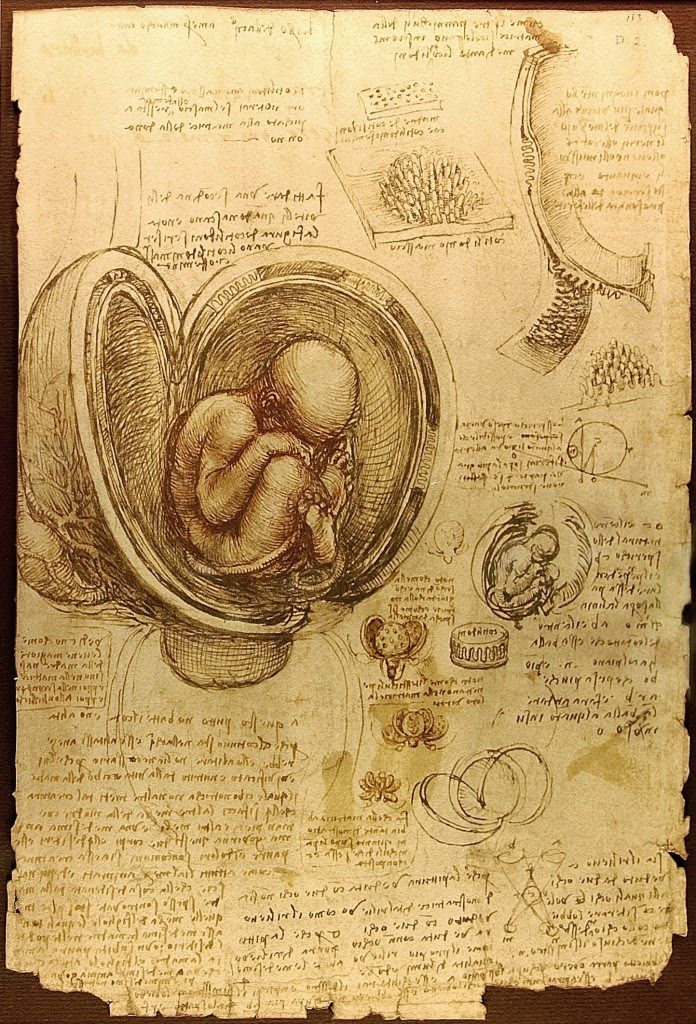
There are several views of this type of connection in the drawing, which can be described as a set of the upper half of bowling-pin shapes pointing upward in a closest-packing layout, while simultaneously, it’s mirror is pointing down from above. These form-sets interlock, their shapes indeed pulling the two sides together once a midpoint of insertion is achieved, securely plugging the two sides together. Imagine now for a moment that these same forms are made from a soft polypropylene-like material, with conductive areas on both the peaks and valleys of the system. Therein lies the form for the new efb interconnect system that will enable durable, repeatable, low insertion force connectivity with high reliability – all while being easily mold-able at low cost.
So far we have a multiple sound input system, as describe above, with 3 equilaterally spaced external ambient microphones per ear, plus a communication, command and control microphone located in the Cymba of each ear. We also have internal storage for local playback of music, and other recordings in the base platform. These ear-worn devices can combine with a modular base station to create a multiprocessor personal compute system. To take the design further, we have a modular, extensible system of stackable electronics functionality packages called efbs to add any number of different types of functionality. What we have not yet discussed is the way in which these sounds get into our ears, and it’s in this physical machine to human interface that lies one of the most important aspects of Bion.
The ear is a fascinating shape, and the design of it helps one to localize sounds. The sensitive aspects are protected from danger up beyond what is called the Meatus area of the Concha. The ear is definitely not round, which literally all rubber tipped earbuds want to assume. And the ear is definitely not a static form, which custom molded hearing aids and high end music monitors tend to be. The former create uneven pressure against the parts of the ear they touch, while the latter only fit when your jaw is in the exact position it was in when the molds were taken (e.g. typically slack-jawed). Talking, singing, chewing, and just moving your jaw changes the internal shape of your ear cavity more than you may realize. No existing designs (except for Bion) seem to take this obvious fact into account. The ideal form then, is the form another layer of skin inside your ear cavity would assume. That is the tack taken by Bion. Like the interconnect system mentioned above, biomimcry and the mantra ‘if this were somehow grown, what would it look like?’ are the lens through which all of Bion’s designs are examined.
Bion employs a micro-thin but tough elastic membrane that inflates gently to hug the inside of your ear cavity precisely. This membrane is disposable, and easily replaceable without tools in seconds. A washable or disposable “comfort sock” made of a fuzzy elastic material covers this (not shown in animation), creating a breathable interface between the inflated elastic membrane and your skin. This allows for pressure equalization and sound porting, so you do not feel like your ears are plugged while wearing them, and sound feedback is eliminated. This inflated membrane becomes the anchor that holds the rest of the device in place; there are no ear hooks or head straps required. Inside this inflated cavity is where the speaker, which is a 28mm woofer, and the balanced-armature driver live. The speaker is situated in a manner similar to an on-ear headphone, while the music monitor and hearing aid quality balanced armature driver is up closer to the eardrum in the tip of this inflatable membrane bladder. When inflated, the bladder expands into the ear, sizing itself accordingly, requiring literally zero insertion force, as can be seen in the animation below. (Note: This animation will say it’s corrupt in Firefox on Linux for some unknown reason. Please view it using Chrome or Chromium browser for Linux instead, where it works just fine…)
Another aspect of the inflated membrane is the way it is designed to protrude through the housing around the main ear-shaped part. These protrusions act simultaneously as padding against the outer part of the ear, and help the enclosure to deliver a deeper, richer sound. These protruding membrane surfaces deliver sound to the surface of the outer ear (or Pinna, as it’s called) 180-degrees out of phase to the primary sound output area into the Concha area of the ear, and also act as a passive radiator / bass reflex type enclosure for the cone woofer. The animation above clearly shows the membrane inflating outward through these tuned ports to form these ‘sound pads’, and the animation below gives another view of this behavior. The end result is a bigger, warmer, more expansive and immersive sound.
Unlike typical earbuds or headphones, Bion employs two speakers per ear; An extremely high-quality balanced armature for delivering the mid-range and highs with exceptional clarity and punctuality, plus a headphone-sized woofer for immersive bass you can feel. Depending on the application outputting to the speakers, one speaker may receive more sound than the other. For example, when listening to music, the larger cone woofer will be more prominent in it’s output than when communicating with others over a wireless connection, which would tend to use the balanced armature driver more for a high degree of clarity in the voice ranges.

Above shows the bladder cover removed, showing the 28mm cone woofer, the balanced armature driver, and the 3C mic in the tip of the Cymba hook.
That’s it for today’s continuous expansion on the Universal Audio Interface, and I hope you enjoyed it. Please leave a comment below.